Voici un petit billet rapide qui a pour objectif de vous présenter RabbitMQ, et plus particulièrement le mécanisme publish/subscribe qu’il propose et qui peut servir afin de faire communiquer plusieurs microservices entre eux.
L’objectif à terme est de pouvoir repenser les divers robots que l’on utilise au HAUM afin de pouvoir les faire communiquer entre eux de manière plus efficace que par IRC qui est actuellement utilisé.
RabbitMQ feat VPN
Je vais vous passer l’étape de l’installation pour directement vous parler de la configuration de RabbitMQ.
Celui-ci permet de faire communiquer des programmes sur la même machine (comportement par défaut) mais également entre plusieurs machines !
Afin de ne pas non plus exposer mon instance à toutes les horreurs qui trainent sur Internet et de me faire détruire mon serveur RabbitMQ, j’ai donc réussi à le configurer pour qu’il soit accessible sur mon VPN uniquement.
Il va donc falloir changer l’interface réseau pour n’écouter que sur l’adresse appartenant au VPN, comme nous l’explique la documentation :
[
{rabbit, [{loopback_users, []}]},
{rabbitmq_management, [
{listener, [{port, 15672}, {ip, "10.1.0.1"}]}
]},
{kernel, [
{inet_dist_use_interface,{10,1,0,1}}
]}
].
On notera que la syntaxe ressemble beaucoup à celle d’Erlang, ce qui est normal car RabbitMQ est lui-même écrit dans ce langage.
L’entrée rabbitmq_management est utilisée parce que j’ai activé l’interface web de RabbitMQ et que je souhaite pouvoir uniquement y accéder en passant par mon VPN depuis mes autres machines.
Programmes de test
Une fois le serveur configuré puis lancé, on va pouvoir s’amuser avec en utilisant des petits scripts Python directement tirés de l’exemple publish/subscribe de la documentation (après avoir créé un environnement virtuel et installé pika ainsi que dateutil pour mon exemple).
Avant le code, je vous propose un petit schéma qui montre comment les programmes peuvent communiquer entre eux grâce au publish/subscribe proposé par RabbitMQ en utilisant des échangeurs et des queues.
J’ai eu la flemme de la refaire en vectoriel donc voici la photo de mon super tableau :
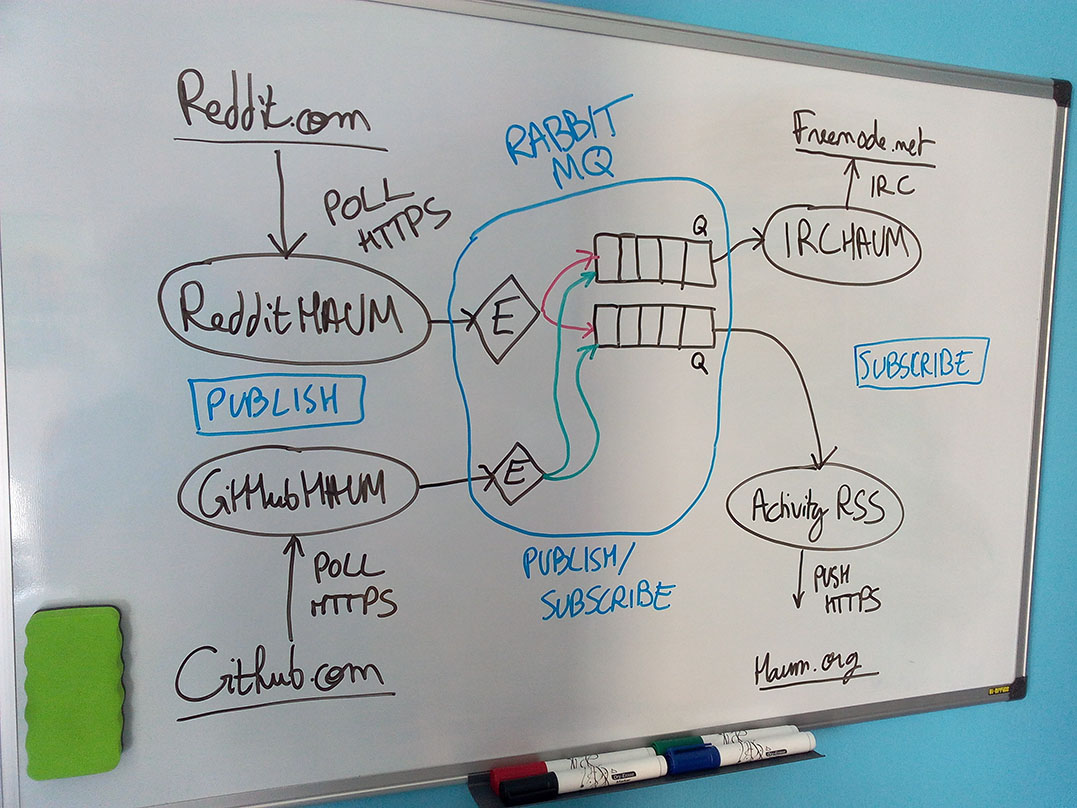
Exemple d’utilisation possible de RabbitMQ avec des microservices
Maintenant que les idées sont plus claires, passons à l’implémentation de découverte pour vérifier que tout fonctionne correctement.
Voici le code (commenté) qui s’abonne à l’échangeur nommé « reddit » :
import pika
import json
import dateutil.parser
# Connexion au serveur via le VPN
conn = pika.BlockingConnection(pika.ConnectionParameters(host='10.1.0.1'))
channel = conn.channel()
# Déclaration de l’échangeur
channel.exchange_declare(exchange='reddit', type='fanout')
# Création de la queue de réception de messages et récupération du nom généré
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# Bind entre l’échangeur et notre queue de réception
channel.queue_bind(exchange='reddit', queue=queue_name)
print(" [*] Waiting for publications. To exit press CTRL+C")
def callback(ch, method, properties, body):
result = json.loads(body.decode('utf-8'))
result['date'] = dateutil.parser.parse(result['date'])
print(result)
# Mise en place du callback lors de nouvelles publications sur l’échangeur
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
# Début de l’attente passive
channel.start_consuming()
Celui-ci va donc attendre de recevoir des chaines de caractères (qui seront en fait des documents JSON) afin de l’extraire et de l’afficher sous forme d’objet Python.
Et voici un exemple de script qui va envoyer une publication sur le même échangeur « reddit » :
import pika
import time
import json
from datetime import datetime
conn = pika.BlockingConnection(pika.ConnectionParameters(host='10.1.0.1'))
channel = conn.channel()
# Déclaration de l’échangeur
channel.exchange_declare(exchange='reddit', type='fanout')
# Dictionnaire à envoyer en JSON
post = {
'name': 'oneshot',
'date': datetime.now().isoformat(),
'author': 'MicroJoe UTF-8 Æ¢V→−≠É–È„⋅®…'
}
message = json.dumps(post)
channel.basic_publish(
exchange='reddit',
routing_key='',
body=message)
print("sent message", message)
conn.close()
L’envoi et la réception fonctionnent très bien, il faut juste ne pas oublier de convertir le message binaire reçu en UTF-8 avant de le lire en JSON pour retrouver toutes les composantes de notre message.
Monitoring
rabbitmq_management est un plugin de RabbitMQ qui permet de voir ce qui se passe sur le serveur. On y retrouve les échangeurs actifs, les queues utilisées, et bien d’autres choses.
Afin de visualiser que l’envoi et la réception de « publications » se passe correctement, nous allons pouvoir regarder les graphiques présents sur la page d’accueil.
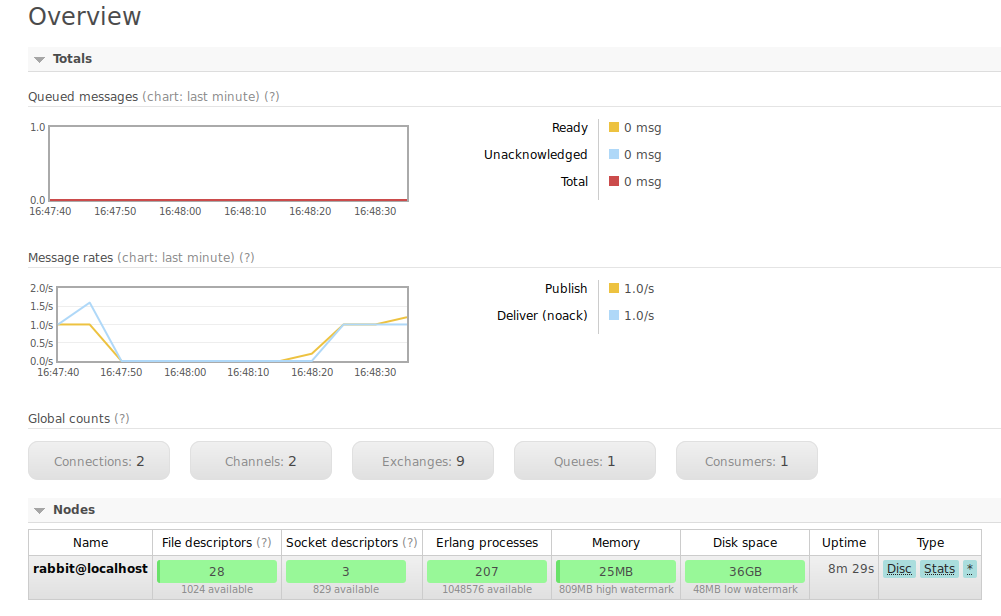
Capture d’écran du manager quand les scripts Python tournent
Le second graphique nous montre le nombre de messages publiés sur le serveur (courbe en jaune) ainsi que le nombre de message transmis (courbe en bleu ciel). Étant donné que nous n’avons qu’un seul script abonné aux publications de l’autre script les courbes tendent à se superposer.
Si on prend deux script qui écoutent alors on aurait deux fois plus de messages transmis que de messages publiés.
Réfléxion sur la volatilité des données
Avec un tel système, si un des nœuds abonnés n’écoute pas lors de la publication d’un nouveau message sur un échangeur alors il rate complètement le message et n’a pas moyen de se rattraper lorsqu’il revient à la vie.
Il faudrait donc penser à un système de validation de réception et RabbitMQ semble pouvoir proposer cet fonctionnalité avec l’utilisation d’une option nommée ack (ça rappellera des cours sur TCP/IP à certains).
On pourrait en parallèle écrire un microservice qui s’occupe exclusivement de stocker tous les messages passés dans une base MongoDB afin de s’assurer d’avoir un backup des messages transmis pour ne pas perdre d’informations en cas de problème (et de la faire rouler sur une fenêtre d’un mois pour éviter de stocker trop de choses).
Conclusion
Il me reste encore pas mal de choses à découvrir mais c’est un bon point de départ et cette techno de passage de messages ouvre pas mal de possibilités quand à la communication entre de nombreux petits programmes simples et indépendants.